Database Indexing: Key Concepts
Introduction
Efficient data retrieval is the foundation of any high-performing database system, and indexing plays an important role in enabling fast access to information. Databases organize data using specialized structures, such as B-tree or hash indexes, which help avoid expensive full table scans and quickly find the rows that matter. Creating effective indexes means improving read speeds without causing excessive work during writes and maintenance. Beyond these fundamentals, modern database systems offer advanced indexing strategies tailored to specific, complex workloads.
There are several crucial factors to consider when it comes to indexing:
- Understanding how different index types, such as clustered and nonclustered, physically organize and speed up data access.
- Knowing how index statistics, such as cardinality and histograms, help the optimizer pick the best way to run queries.
- Designing indexes that align with query patterns, sorting needs, and data loading workflows to maximize overall efficiency.
Mastering these concepts enables database professionals to create indexing strategies that can improve query speed, reduce resource consumption, and maintain scalability as data volumes grow. In this article, we explore how indexing helps improve query performance; sorting; extract, transform, and load (ETL) processes; and routine maintenance.
Summary of key database indexing concepts
Concept | Description | ||
|---|---|---|---|
Indexing fundamentals | Indexes are data structures designed to improve retrieval speed by minimizing the need to scan entire tables. | ||
Index statistics, density, cardinality, and histograms | Optimizers can improve query plans and minimize I/O by using up-to-date statistics to accurately estimate row counts. | ||
Optimal indexing for query performance | Well-designed indexes that match query patterns reduce costly scans and enhance execution efficiency. | ||
Optimal indexing for sort operations | Well-designed indexes that align with sorting and filtering conditions can eliminate unnecessary sort operations, reducing CPU usage and temporary storage needs. | ||
Indexing strategies for specific workloads | Advanced indexing strategies, such as filtered, functional, and columnstore indexes, optimize complex queries beyond standard B-trees. | ||
Indexing and ETL operations | Minimizing or disabling indexes during bulk loads improves ETL speed and reduces write overhead. | ||
Index maintenance and observability | Regularly monitoring and maintaining indexes prevents fragmentation, removes unused indexes, and sustains performance. |
Indexing fundamentals
Indexes help databases quickly locate rows of interest without having to scan the entire table. Without indexes, the system must check each row one by one, which becomes slower as the tables grow. Indexes significantly improve read performance by narrowing the search path, although they require extra storage and add a small cost for data modifications.
Index seeks and scans
To understand how indexes make things faster, it helps to know the difference between an index seek and an index scan. Index seeks target specific rows using the index key, and are the most efficient since the database goes directly to the data it needs. An index scan is the operation where the database must go through a portion of the index, or maybe the entire index, to find the data. While not as fast as a seek, it's still often much quicker than a full table scan, especially in the case of a “covering index” that contains all the columns a query needs. This is an important distinction because, as database expert Brent Ozar points out in his , a scan isn't always bad; sometimes it's the most efficient way to get the job done.
Clustered and nonclustered indexes
There are two primary types of indexes to understand: clustered and nonclustered. A clustered index organizes the actual rows in the table according to the index key, meaning the data is physically stored in that order. Since a table can only be sorted one way on disk, it can have only one clustered index. However, not all database systems support clustered indexes in the same way. For example, SQL Server® uses them natively, but PostgreSQL® doesn't implement traditional clustered indexes; instead, it allows a one-time CLUSTER operation to reorder data physically, which is not maintained automatically. MySQL® with InnoDB® supports clustered indexing, but it automatically uses the primary key as the clustered index.
In contrast, a nonclustered index doesn't alter the physical order of data. Instead, it maintains a separate structure that stores key values, pointing to the exact location of each row. This allows multiple nonclustered indexes on the same table, each tailored to different queries. This is similar to a reference book that may have multiple indexes for various subjects or contributors.
Indexing methods
Having seen how indexes help locate data and the differences between clustered and nonclustered types, it will be useful to look at the underlying structures that power them. Understanding these structures could help explain why certain indexes are better suited for specific types of queries.
The most widely used indexing method across database systems is the B-tree index. It's well-suited for both equality and range-based queries because it maintains a balanced tree structure, allowing searches to be completed in logarithmic time regardless of table size.
B-tree indexes are composed of pages arranged hierarchically. A root page points to intermediate pages, which finally point to leaf pages containing actual data or row pointers. The depth of the tree affects the number of page reads needed for a lookup. For example, a table with millions of rows might still be accessed with only three to four page reads thanks to the balanced tree structure. SQL Server also allows you to set a “fill factor” for indexes to specify the percentage of space to leave free on each page to reduce page splits during inserts and updates.
While B-trees are versatile, other index types are better-suited for niche scenarios. Hash indexes excel at pinpointing exact matches quickly, but aren't designed for range lookups. Bitmap indexes are ideal for columns that have only a few unique values, such as status flags or gender, making them popular in data warehousing. For analytical workloads involving massive tables, columnstore indexes shine by storing data in columns instead of rows, enabling fast aggregations and scans over large volumes.
Here's a summary of common index types:
Index Type | Best For | Typical Use Cases | |||
|---|---|---|---|---|---|
B-tree | Equality and range queries | Primary and foreign keys, general-purpose indexing | |||
Hash | Exact equality lookups | Caching or fast lookups on unique values | |||
Bitmap | Low-cardinality data | Data warehousing, reporting on columns with few distinct values (e.g., gender and status) | |||
Columnstore | Analytical queries | Data warehousing, large tables with complex aggregations |
Index statistics, cardinality, and histograms
To run a query efficiently, a database first needs a good understanding of the data. The part of the system that figures out how the query will be executed is called the optimizer, and it relies on statistics to make smart decisions. The diagram below shows how the uses the query, schema, and statistics to produce an execution plan.
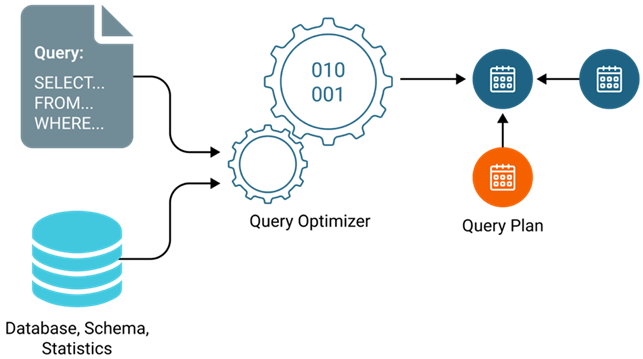
Flow of SQL query optimization from input to execution plan ().
These statistics help the optimizer estimate the number of rows a query will return, which in turn helps it decide whether to do a fast index seek or a slower table scan. The optimizer can make a bad decision if the statistics are outdated, leading to a slow query.
Two key concepts in statistics are cardinality and density:
- is the number of unique values in a column. A column with high cardinality, such as a unique ID, is perfect for an index because it allows the database to quickly and accurately find a small number of rows. A column with low cardinality, such as a status column with only three values (e.g., active, inactive, or pending), is not as suited for a traditional B-tree index because a search might still return a large number of rows.
- Density measures how many times (on average) a value is duplicated in a column. A high-density column means there are many duplicate values, which makes an index less effective for precise lookups.
To handle data that is not evenly distributed, databases use histograms. Imagine you have a column with ages, but most of your users are between 20 and 30 years old. A simple average would not tell the optimizer the full story. A histogram breaks the data into buckets and counts the number of rows in each one. This gives the optimizer a more accurate picture of the data, enabling it to create a more effective query plan. Keeping these statistics fresh is vital.
As data is inserted, updated, and deleted, the underlying distribution can change. If statistics are not updated, they become stale and no longer reflect the current state of the data, causing the optimizer to choose an inefficient query plan. This is why statistics must be refreshed regularly, either automatically by the database or through scheduled maintenance. SQL Server stores histograms in up to 200 steps per column (and an additional step for NULLs), where each step represents a range of values and the number of rows within that range. The optimizer uses these histograms to estimate , which drives decisions such as join order and choice of index access. High selectivity indexes (those that return few rows for a given key) are generally preferred for seek operations. Out-of-date statistics can lead to severe query plan misestimation, which is why automatic statistics updates or proactive refresh with commands, such as UPDATE STATISTICS, are recommended.
For example, in SQL Server, you can manually refresh statistics with:
-- Update statistics for a specific table
UPDATE STATISTICS Users;
-- Update all statistics in the database
EXEC sp_updatestats;
can raise alerts for stale Oracle® statistics or ineffective SQL Server/Azure SQL® statistics, helping DBAs proactively refresh statistics and maintain efficient query performance.
Optimal indexing for query performance
The most common reason people create indexes is to make their queries run faster. The goal is to let the optimizer replace a slow, costly full table scan with a quick, efficient index seek. To do this, you need to design your indexes to match the way your application queries the data. For queries that filter on multiple columns, creating a composite index that aligns with your WHERE, JOIN, and ORDER BY patterns is a key strategy for improving efficiency.
Using a covering index is a good way to enhance the performance of your queries. This is a special type of index that includes all the columns a specific query needs. By using a covering index, the database can get all the information it needs from the index itself, without having to go back to the main table. This is referred to as an index-only scan and often provides a major speed advantage. The INCLUDE clause in SQL Server lets you append nonkey columns to an index, allowing it to handle more queries without changing the main key structure of the index.
The example below shows what a covering index looks like in SQL Server:
CREATE NONCLUSTERED INDEX IX_Customer_Name_City
ON dbo.Customers (LastName, FirstName)
INCLUDE (City, State);
This index can efficiently handle a query such as “SELECT LastName, FirstName, City, State FROM Customers WHERE LastName = 'Smith'” because all the required columns are in the index itself. A covering index not only provides fast lookups but also avoids the need for a key lookup (bookmark lookup in SQL Server). A key lookup occurs when an index does not include all the required columns, forcing the optimizer to fetch the missing columns from the clustered index or the heap. By including nonkey columns, a covering index transforms multiple I/O operations into a single index-only scan, significantly reducing query cost.
To determine if your indexes are doing their job, you need to look at execution plans. Tools such as EXPLAIN in PostgreSQL or the graphical execution plan in SQL Server show you exactly how the database plans to run a query. You can see if it is using an index seek, an index scan, or the dreaded table scan.
Tools such as DPA take this a step further. The index advisor feature of DPA automatically pinpoints costly queries by analyzing top SQL and wait-time trends, then provides specific recommendations for which indexes to create, drop, or modify. This proactive approach ensures you know exactly which queries need tuning the most.
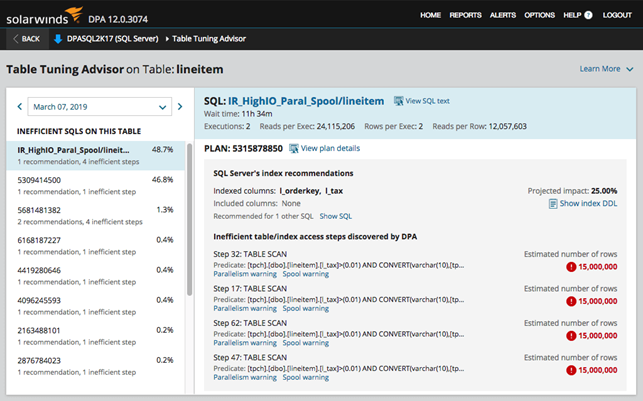
SQL Server tuning with the index advisor in Database Performance Analyzer.
Optimal indexing for sort operations
Sorting data is a common but resource-intensive task. When you have an ORDER BY or GROUP BY clause in your query, the database must sort the results. If there is no suitable index to support the sort, the database engine needs to perform an explicit sort operation, which can be CPU-intensive and may also spill over to temporary disk storage for large datasets. This is where a well-designed index can significantly improve performance by avoiding the need for a full sort altogether.
By creating an index that matches the order of your ORDER BY or GROUP BY clause, you can provide the database with presorted data. For example, an index on (last_name, first_name) would allow a query with ORDER BY last_name, first_name to read the data in the correct order, eliminating the need for a separate sort step. This results in significant savings for CPU and temporary storage resources.
When designing a multi-column index, it is good practice to place the columns used for filtering and sorting in the correct order from left to right. To illustrate this, we created and populated a large orders table in a PostgreSQL 14 database.
EXPLAIN ANALYZE
SELECT order_id, amount, order_date
FROM orders
WHERE product_category = 'Electronics'
ORDER BY order_date DESC
LIMIT 100;
The EXPLAIN ANALYZE command will show the query plan and the total execution time.
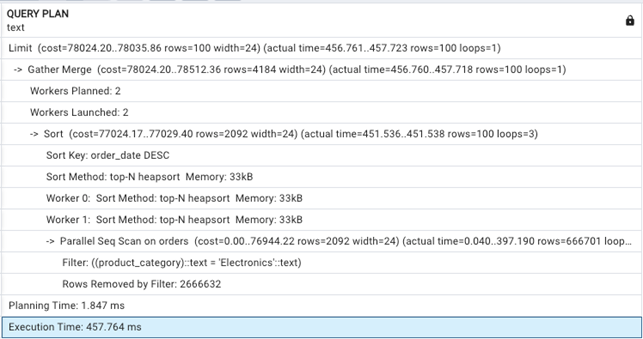
Next, we will create a composite index specifically designed to support this query. The index covers both the WHERE clause (product_category) and the ORDER BY clause (order_date DESC).
CREATE INDEX idx_orders_category_date_desc ON orders (product_category, order_date DESC);
While the index uses order_date DESC to match the query's sort order, it's not strictly necessary because PostgreSQL can scan B-tree indexes in both directions.
We will run the same query again, but this time with the new index in place.

The practical impact of a well-designed index is immediately apparent when comparing the two query plans. The initial query, running without a supporting index, required 457.764 milliseconds (ms) to complete. Its plan shows a Parallel Seq Scan, which means the database had to laboriously read through a large portion of the entire table to find all matching rows. Then, it had to perform a separate sort operation to order the results, a costly step that can consume significant CPU and memory. In contrast, the second query, with the idx_orders_category_date_desc index in place, finished in a mere 0.667 ms, which is over 680 times faster. The new plan shows a direct index scan on the newly created index, which eliminates the need for both the slow table scan and the expensive sort. This demonstrates precisely how a composite index can transform a resource-intensive query into a fast, efficient lookup.
For large datasets such as time series or logs, special index types can make sorting more efficient. The PostgreSQL Block Range Index (BRIN) indexes, for example, are great for data that is naturally ordered by time or another key. They work by storing a summary of the data in a block, which allows the database to skip entire sections during a query.
For partitioned tables, such as those in SQL Server, the optimizer can focus its sorting efforts on a specific partition, which is much faster than sorting the entire table. When indexes match the ORDER BY clause, the database can often avoid a separate sort operation, which saves CPU and memory. In parallel query execution, SQL Server and PostgreSQL can distribute index scans across threads, but if a sort is required, it can become a bottleneck.
Indexing strategies for specific workloads
Modern systems offer specialized index types that are essential for optimizing specific, complex workloads, although B-trees remain the general workhorses of database indexing. A deeper understanding of these can elevate your performance tuning skills.
Filtered/partial indexes
Instead of indexing an entire large table, you can create a more efficient nonclustered index that includes only a subset of rows. This is known as a filtered index in SQL Server and a partial index in PostgreSQL. By applying a WHERE clause to the index itself, you can drastically reduce its size and the overhead of maintaining it. For example, for a Tickets table with many closed records, an index built only on the open tickets allows queries to find relevant data much more quickly without having to scan a bloated, full-table index.
CREATE NONCLUSTERED INDEX IX_Tickets_Open
ON Tickets (CreatedDate)
WHERE Status = 'Open';
Expression/functional indexes
Not every query filters on plain column values. In practice, developers often apply transformations such as converting text to lowercase, extracting parts of a date, or applying math functions. The problem is that without special indexing, these transformations can block the optimizer from using a regular B-tree index, forcing a full table scan.
This is where functional (expression) indexes step in. In PostgreSQL, you can directly index the result of an expression. For example, if users log in with case-insensitive emails, queries often include LOWER(email). A normal index on the raw email column does not help, but a functional index on LOWER(email) lets the query planner match exactly what's being searched.
CREATE INDEX idx_lower_email
ON customers (LOWER(email));
A lookup like this can leverage the index, avoiding a costly scan:
SELECT * FROM customers WHERE LOWER(email) = 'ruli@example.com';
SQL Server doesn't support functional indexes natively, but it offers a workaround: computed columns. By persisting a computed value (e.g., LOWER(email) stored as a generated column), you can create a regular index on it. MySQL follows a similar approach, using generated columns that can also be indexed. This achieves the same performance benefits while keeping the optimizer satisfied.
In both systems, the key advantage is flexibility, as you are not limited to indexing raw columns but can index data the way queries use it.
Columnstore indexes for HTAP
Traditional B-tree indexes are great for quick lookups, but they struggle when queries must scan and aggregate huge tables. Columnstore indexes solve this by storing data by column. As a result, they boost compression and speed up analytics.
In SQL Server, columnstore indexes power Hybrid Transactional and Analytical Processing (HTAP). This lets you insert new orders into (for example) a sales table while analysts run real-time reports, without waiting for ETL. SQL Server achieves this by combining a rowstore for fast writes with a columnstore for scans and aggregations.
PostgreSQL doesn't include native columnstore indexes, but extensions such as TimescaleDB offer columnar-like compression for time-series data. Foreign data wrappers (FDWs) can also provide access to external columnar stores, such as Parquet.
Columnstore indexes bridge the gap between transactional and analytical systems by aligning data storage with analytic patterns. This feature often makes the difference between batch reports and live dashboards for organizations seeking real-time business intelligence.
Indexing and join algorithms
Indexes are not only for WHERE clauses; they are essential for efficient join operations. The database query optimizer chooses a join algorithm based on available indexes and statistics:
- Nested loop join: The database scans the “outer” table (also known as the driving table) and, for each row, it uses a separate loop to find matching rows in the “inner” table (also known as the driven table). This is most efficient when the inner table has an index on the join key, as the inner loop becomes a fast index seek instead of a slow table scan.
- Merge join: This requires both joined tables to be sorted on the join key. If a table has an index on the join column, the database can use the presorted data and avoid an expensive sorting step.
- Hash join: The database builds a hash table in memory from the smaller of the two tables, then scans the larger table and probes the hash table for matches. Indexes are not directly used in the join itself, but they can help the optimizer decide which table is smaller or how to retrieve data more efficiently before the join.
Indexing and extract, transform, and load operations
ETL processes involve moving huge amounts of data, and indexes can slow them down. Every time you insert a new row, the database has to update every single index on that table. This adds a significant amount of extra work, making a bulk load take much longer than it should.
A common and effective strategy is to drop or disable any nonessential indexes on the target table before starting a bulk load. Once the data is loaded, you can rebuild the indexes. Rebuilding an index in a single operation is usually much faster than updating it one row at a time. It also gives you a fresh, unfragmented index.
This SQL Server example shows how to disable and rebuild an index for a bulk load:
-- Disable the index before the bulk load
ALTER INDEX IX_Sales_Date ON dbo.Sales DISABLE;
-- Rebuild the index after the bulk load
ALTER INDEX IX_Sales_Date ON dbo.Sales REBUILD;
It's important to weigh the cost of disabling and later rebuilding indexes. For large datasets, index rebuilds can consume significant amounts of time and resources. In such cases, it may be more efficient to use incremental loads (loading only new or changed data) or partitioning strategies (splitting tables into smaller, manageable segments).
Clustered indexes, which define the physical row order, tend to be more sensitive to write-heavy ETL operations. If possible, it would be better to defer creating the clustered index until after the data load is complete.
Staging tables, especially those with no or minimal indexing, are another useful tactic. They allow for quick loading and transformation before moving the cleaned data into the final, fully indexed production tables.
Modern databases offer special features to speed up these processes. has minimal logging for certain bulk operations, which reduces the amount of data written to the transaction log and speeds up inserts. PostgreSQL has “unlogged” tables, which are great for staging data temporarily because they don't have the overhead of transactional safety. You can load data into an unlogged table, transform it there, and then quickly move it to your final, indexed table.
Another consideration in ETL performance involves how indexes interact with the transaction log and recovery models. For instance, by reducing log writes for bulk operations while maintaining point-in-time recovery for other transactions, the bulk-logged recovery model of SQL Server can achieve a balance between speed and recoverability. In PostgreSQL, the COPY command not only improves bulk insert performance but also minimizes the overhead of index maintenance by efficiently batching data inserts. Similarly, the direct path insert in Oracle avoids the buffer cache and can delay index updates until after the data is written, reducing the impact on index performance during large loads.
Index maintenance and observability
Over time, indexes can become fragmented, much like a hard drive. Fragmentation occurs when the logical order of the index pages no longer matches their physical order on the disk. This forces the database to jump around to find the data, which is slower than reading it sequentially. Regular index maintenance is necessary to keep your queries running fast, especially for large, heavily used indexes.
The two primary methods for addressing fragmentation are reorganization and rebuilding. Reorganization is a lighter-touch operation that shuffles the pages back into the right order. It's great for indexes with a low to moderate level of fragmentation (e.g., 5% – 30%). For more severe fragmentation (e.g., over 30%), a full rebuild is often necessary. This process drops and recreates the index from scratch, making it perfectly compact and ordered.
It is also important to monitor which indexes are being used. An unused index is a waste of space and adds unnecessary overhead to write operations. Databases have built-in tools for this, such as dynamic management views in SQL Server or pg_stat_user_indexes in PostgreSQL. However, checking them manually for multiple indexes can be time-consuming.
Tools such as DPA automate this process by giving a clear picture of index usage, alerting you to fragmentation issues, and suggesting which indexes you might be able to get rid of. This helps free up storage, reduce memory consumption, and minimize the write overhead.
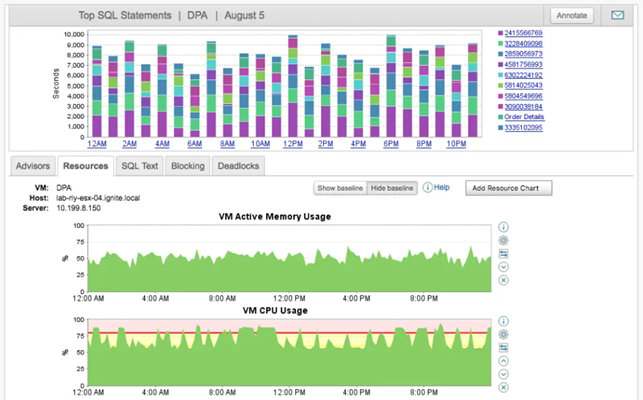
Database Performance Analyzer dashboards reveal SQL Server index fragmentation and performance bottlenecks.
Beyond fragmentation, another critical factor is index page compression and storage overhead. SQL Server supports row-level and page-level compression, which can shrink index size on disk and in memory. It improves cache utilization and reduces I/O at the cost of some extra CPU usage during reads and writes. PostgreSQL offers similar benefits through The Oversized-Attribute Storage Technique (TOAST). It automatically compresses large column values, reducing index bloat when working with wide tables.
Another subtle aspect is fill factor tuning. Adjusting the amount of free space required per page can reduce page splits for write-heavy workloads but may increase storage usage. DBAs have more control over performance by routinely examining compression, fill factor settings, and index bloat statistics.
Final thoughts
Effective database indexing is fundamental to improving data access and ensuring queries run smoothly. Indexing is a practice of balancing performance, as the benefits of read operations come with a cost to write operations. This is especially true during large ETL processes, where temporary index management is key. Consistent maintenance prevents fragmentation from degrading performance over time.
The best indexing strategies are combined with observability. Tools such as SolarWinds Database Performance Analyzer provide crucial insights into query bottlenecks and index health, ensuring databases remain performant and scalable as workloads grow.